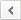|
빅데이터가 ADHD 특성 파악 및 진단에 활용될 가능성 탐색해
빅데이터는 다양한 산업 분야에서 신가치 창출에 활용되고 있으며, 의학 분야에서도 임상 관련 데이터를 분석해 질병에 대한 새로운 진단 및 치료 방법을 제시하는 연구가 점차 활성화되고 있다. 최근 강남세브란스병원 정신건강의학과 김은주 교수와 경성현 박사 연구팀은 빅데이터 기반의 ‘위상수학(topology)' 분석을 활용해 주의력 결핍 과잉행동 장애(ADHD) 아동의 뇌영상을 구분하는 새로운 연구 결과를 발표했다.
흔히 ADHD라 불리는 ‘주의력결핍과잉행동장애’는 소아청소년기의 대표적인 뇌질환으로 학습 부진, 게임 중독 등의 행동 문제를 일으키는 대표적 원인이다. 그동안 주의력 결핍 과잉행동 장애는 부모나 선생님의 보고, 설문지 작성, 행동 관찰 등의 방법에 의존하여 진단했기 때문에 뇌영상 자료 등이 실제 임상에서 활용되지는 않았다.
이번 강남세브란스병원 김은주·경성현 연구팀은 객관적 신경생물학적 데이터에 위상수학 데이터 분석 방법을 뇌영상 분석에 적용한 연구를 실시해 진단의 신뢰성을 높이고, 뇌영상이라는 객관적 데이터에 근거해 질환을 진단할 수 있는 길을 제시한 것이다. 위상수학(topology, 토폴로지) 데이터 분석은 데이터 사이의 유사성을 찾아 일종의 형태(네트워크)를 만들어 냄으로써 기존에 보이지 않던 데이터 특성을 시각적으로 보이는 연구 방법이다.
김은주·경성현 연구팀이 400여 명의 주의력 결핍 과잉행동 장애(ADHD) 환자 및 정상발달 아동의 뇌영상(fMRI) 자료를 위상수학 데이터 방법론으로 분석한 결과를 시각화 한 그래프는 아래 <그림1>과 같다.
연구 결과에 따르면 그래프 상의 노드가 파란색일수록 뇌영상 상에서 ADHD 아동에서 나타나는 질환요소가 거의 없는 정상발달 아동군, 붉을수록 그 반대로 큰 환자 군이라고 해석할 수 있다. 또한, 연구팀은 분석을 통해 정상 아동에서는 노드가 파란색일수록 지능지수(IQ)가 높고, ADHD(주의력 결핍과잉행동장애) 아동군에서는 노드가 붉을수록 증상도가 심하고, 동반되는 다른 정신과적 질환의 수도 증가한다는 것을 밝혔다. 뿐만 아니라, 정상군이나 환자군 둘 중 하나로만 진단하던 기존의 분석법과 달리 위 그래프에서 초록 또는 노란색으로 표시되는 노드 구간을 ‘ADHD 구분이 모호한 영역’으로 구분해 시각화할 수 있게 됐다.
김은주 교수는 “주의력결핍과잉 행동장애 연구에 뇌영상 데이터를 활용하기 위해 위상수학 데이터 분석을 처음으로 적용한 것이다. 거대하고 복잡한 임상 자료를 분석해 그 안에서 새로운 패턴을 발견하고, 이를 통해 주의력결핍과잉 행동장애 환자의 특징을 객관적으로 범주화한 것이다”라고 연구의 의의를 밝혔다.
공동 연구자인 경성현 박사는 “실제로 빅데이터가 질병 진단이나 환자 특성 파악에 어떻게 활용될 수 있는지를 확인했다”며 “ADHD 환자 뿐 아니라 다른 환자군의 특성 분석에도 활용될 수 있는 만큼, 차세대 의학의 미래를 보여주는 기초 연구가 되기를 바란다”고 말했다.
연구 결과는 지난해 9월, 미국 공공과학 도서관 온라인 국제학술지인 PLoS One(임팩트 지수=3.23)에 소개됐다.
<참고> 토폴로지 데이터 분석 방법
토폴로지 데이터 분석은 크게 네 단계로 나눌 수 있다. 첫 번째는 필터 함수를 구성하는 것이다. 필터 함수의 역할은 고차원의 데이터의 모양을 가장 잘 표현할 수 있도록 데이터를 처리하는 것이다. 두 번째는 거리 함수를 정의하는 것이다. 고차원의 데이터가 필터함수를 통해서 하나의 값으로 요약되고 나면, 필터 값을 기준으로 데이터를 구획화 하게 되고, 구획화된 데이터 값들 간의 거리를 계산하게 된다. 세 번째는 클러스터링 방법이다. 필터값에 따라서 데이터를 구획화 하고, 구획화된 데이터 값들 간에 거리를 구하고 나면, 이후에는 데이터 값들 간의 거리를 기준으로 클러스터링을 하게 된다. 해당 필터 구간내에 몇 개의 데이터들이 서로서로 모여 있는지, 아니면 2~3개의 덩어리로 서로 뭉쳐 있는지 등이 클러스터링을 통해서 계산되게 된다. 마지막으로 데이터 시각화가 필요하다. 데이터 분석으로 얻은 결과를 그래프의 형태로 표현하는 것으로 각 노드(node)는 클러스터이고, 선(edge)는 클러스터간의 교집합이 존재함을 표현한다. 마지막으로 노드의 색은 각 노드 내의 데이터 값이 갖는 필터함수 값의 평균 수치로 표현되는 것이다.
|